archiveOS
Desktop app · Personal · 2026
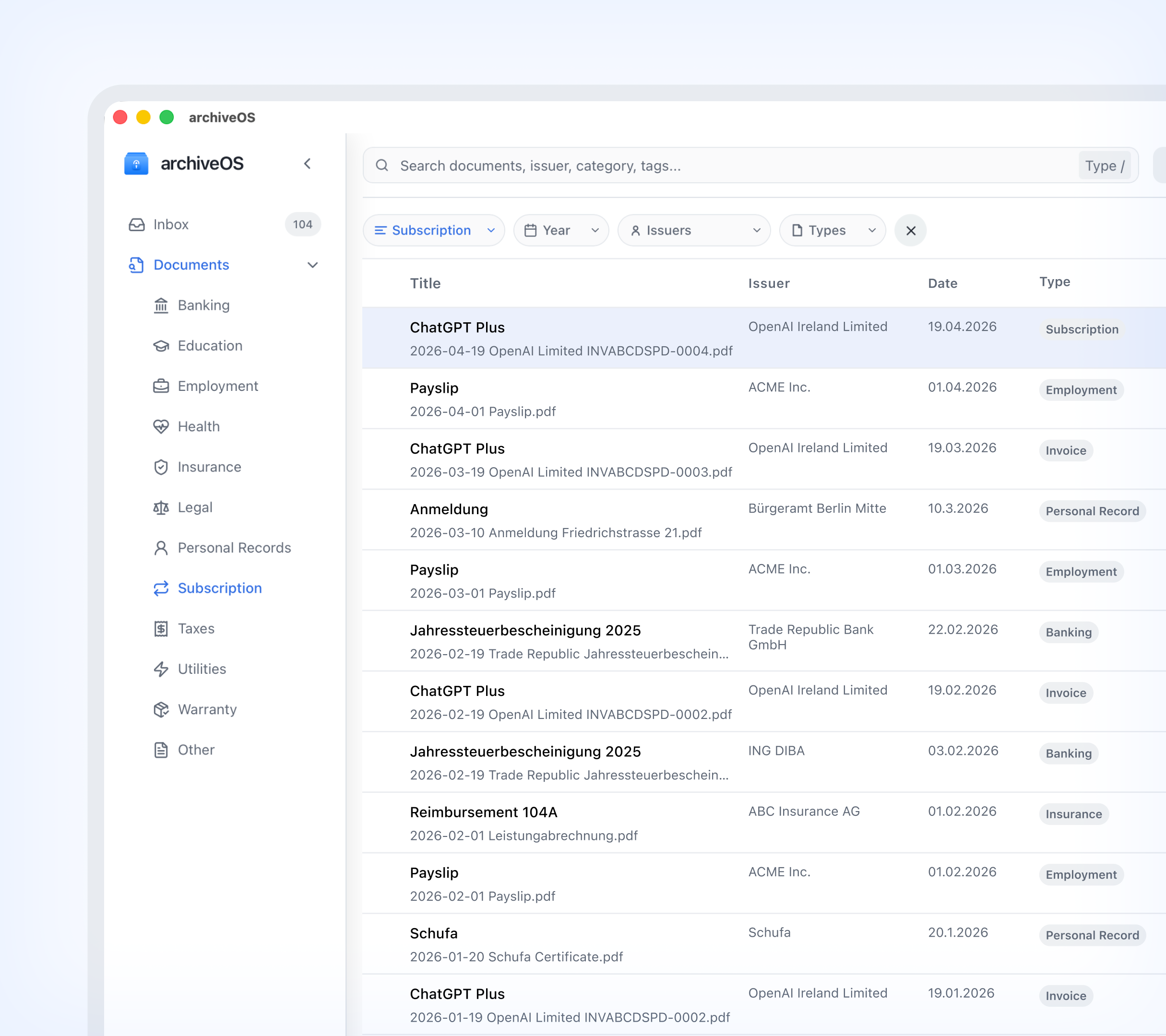
Replaced ad-hoc file storage with a deterministic retrieval system for long-term, high-stakes document access.
Designed and built a local-first archive system that separates storage from structure, enabling consistent ingestion, secure storage, and reliable retrieval of documents years after they were created.
> Key decisions
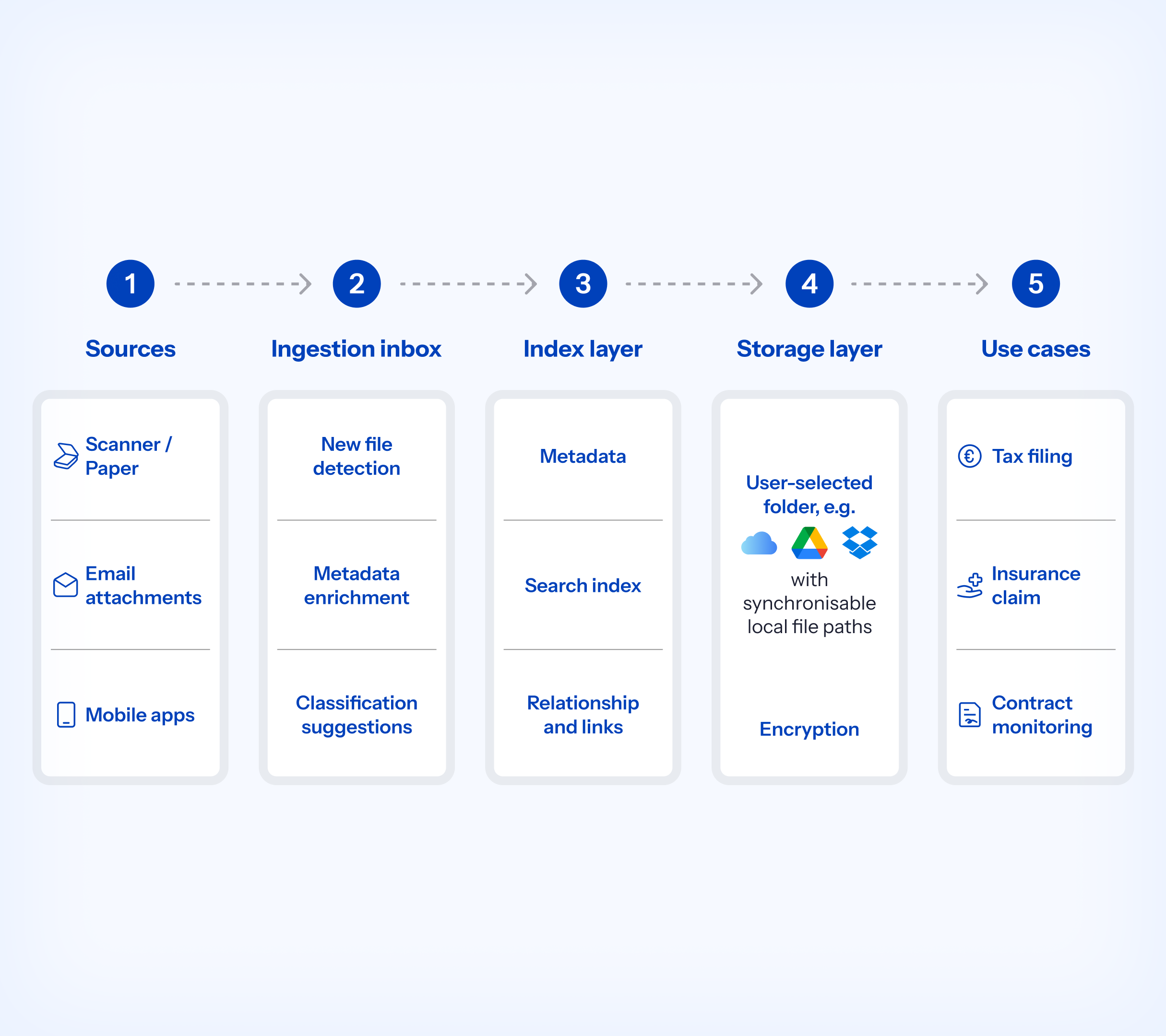
01/ Decouple storage from the product layer
User-selected storage providers handle sync, not structure or retrieval.
Impact
- > Compatible with any provider syncing to disk such as iCloud or Google Drive
- > No dependency on external APIs or vendor lock-in
- > Ensures portability over long retention periods
02/ Separate index from file system
Files are inconsistent, so structure must be independent.
Impact
- > SQLite-backed metadata index
- > Files remain unchanged and accessible outside the app
- > Structure can evolve without migrating files
03/ Introduce an ingestion inbox
Documents arrive incomplete and inconsistently formatted.
Impact
- > All files enter a staging layer before classification
- > Ingestion does not block on missing information
04/ Design for incomplete and uncertain data
Real-world inputs are messy and often lack key fields.
Impact
- > Defaults and inferred metadata reduce input burden
- > The system remains queryable even with partial information
05/ Prioritise deterministic retrieval paths
Users do not navigate hierarchies under pressure.
Impact
- > Query-based retrieval across entity, timeframe, and document type
- > Defined retrieval paths for recurring scenarios such as tax year, insurer, and account
06/ Add optional file-level encryption
Provider-level security is insufficient for sensitive documents.
Impact
- > Decryption and viewing are restricted to the application
- > Adds a second security layer while maintaining user ownership
- > Introduces dependency on the app for access to encrypted files
> Trade-offs
01/ Structure vs ingestion friction
- > More structure improves retrieval reliability
- > Mitigated through staged enrichment and metadata defaults
02/ Portability vs deep integration
- > Provider-agnostic architecture avoids lock-in
- > Limits use of cloud-native features
03/ Encryption vs accessibility
- > Stronger security guarantees for sensitive files
- > Reduced usability outside the system
04/ Automation vs correctness
- > Full automation risks incorrect classification
- > Manual-first ingestion ensures reliability
> Situation
- Product
- > Personal document operating system (desktop, local-first)
- Users
- > Individual (myself and anyone living in Germany)
- Environment
- > Germany, with 10-year docuemnt retention across personal, tax, and financial records
- Storage model
- > User-selected folders synced via providers such as iCloud or Google Drive
- Constraints
-
- > Documents originate from fragmented sources such as paper, PDFs, email, and portals
- > There is no consistent metadata or naming standard at the point of ingestion
- > Retrieval failure carries real cost in audits, claims, and missed deadlines
- > Long-term durability is required across 10 or more years
- > Data ownership and portability must be preserved
- > Sensitive documents require stronger guarantees than provider-level security
> Problem
Document storage is solved. Retrieval is not.
Files accumulate across folders and cloud providers without a system that guarantees they can be found again. Over time, naming conventions drift, context is lost, and documents become effectively invisible.
The failure mode is not missing data. It is inability to retrieve the correct document with confidence under time pressure, often years after ingestion.
> Approach
Treated archiving as a system design problem under real-world constraints, not a file organisation task.
Principles
- > Separate structure from storage
- > Optimise for retrieval, not organisation
- > Accept incomplete inputs and evolve structure over time
- > Maintain user control over files and storage
> Execution
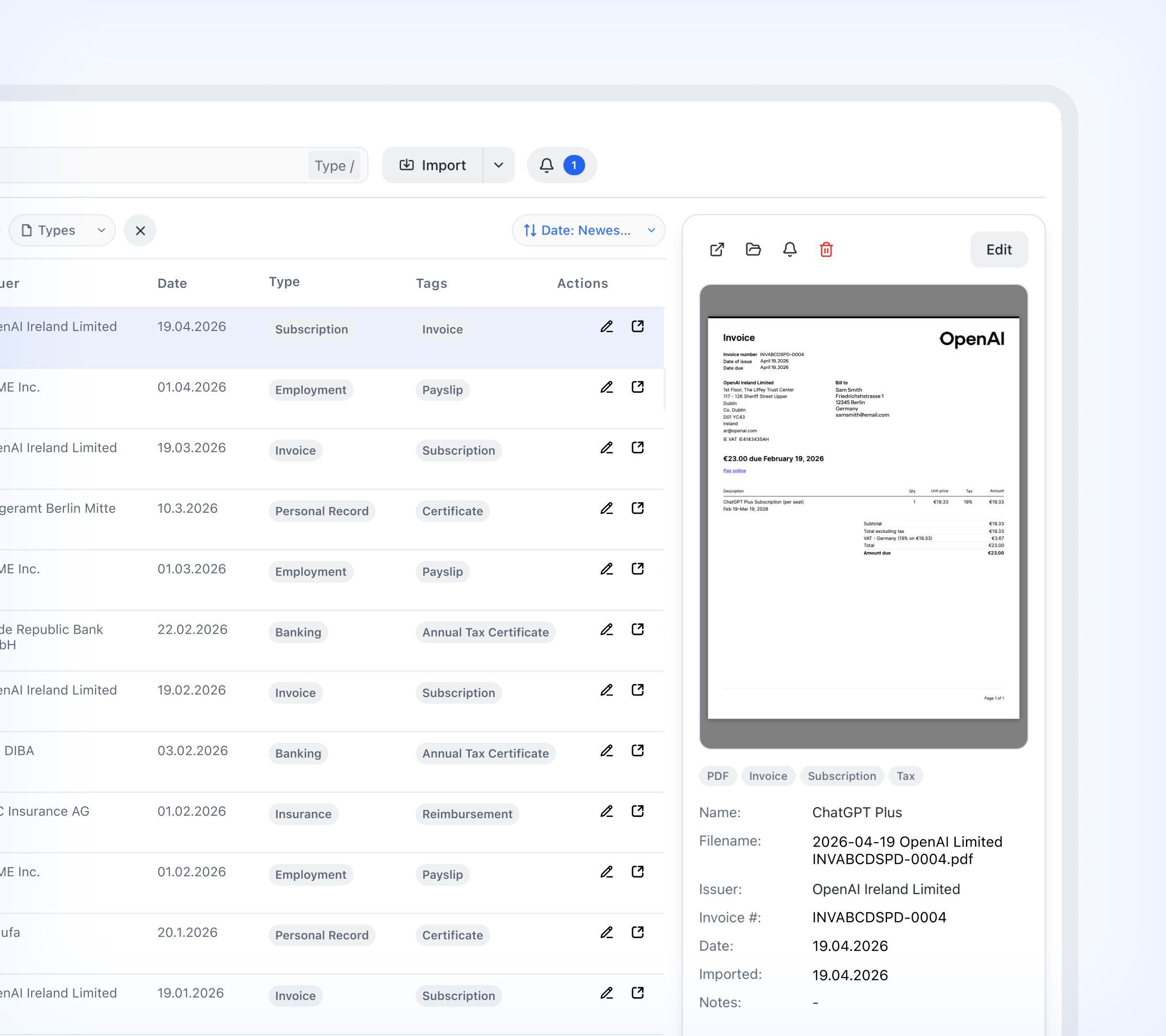
- > Built a Mac OS desktop application using Tauri and SQLite with a local-first architecture
- > Implemented folder-based ingestion where the user selects a root directory, local or synced via iCloud or Google Drive
- > Defined a document schema across type, issuer, counterparty, and relevant dates
- > Built an ingestion pipeline from file to inbox to metadata enrichment to indexed record
- > Added an optional file-level encryption layer with controlled decryption and viewing inside the app
> Results
- > Retrieval shifted from multi-source search to a single, deterministic lookup
- > File storage became provider-independent and portable
- > Archiving became a continuous workflow instead of a periodic clean-up task
- > Sensitive documents gained an additional application-level security layer